Unicode Normalizer
An asset by Goutte
Install Asset
Install via Godot
To maintain one source of truth, Godot Asset Library is just a mirror of the old asset library so you can download directly on Godot via the integrated asset library browser

Quick Information

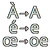
Unicode Normalizer
Tookit to handle removing diacritics and substitutable characters from unicode strings.Provides a UnicodeNormalizer singleton that helps normalize your unicode strings by :- removing diacritics (decomposing, then keeping only the first character)- substituting fallback characters- being blazingly fast (binary search)- being lightweight- being extensibleIts replacement database is built from the official unicode.org data. It is only about 16Kio.Usage Example :You can use the `normalize` method on the autoload singleton `UnicodeNormalizer`:UnicodeNormalizer.normalize("Dès Noël, où un zéphyr haï me vêt")# "Des Noel, ou un zephyr hai me vet"You can also exclude some characters from the normalization by removing the from the mapping :var allowed_decomposables := "éàè"for i in allowed_decomposables.length():UnicodeNormalizer.mapping.remove_decomposable(allowed_decomposables.unicode_at(i))Finally, the UnicodeNormalizer is made to be extended, in order to adapt to specific needs.
Supported Engine Version
4.0
Version String
0.1.2
License Version
MIT
Support Level
community
Modified Date
2 years ago
Git URL
Issue URL
Unicode Godot Addon
Tookit to handle removing diacritics and substitutable characters from unicode strings.
UnicodeNormalizer
This singleton helps normalize your unicode strings by:
- removing diacritics (decomposing, then keeping only the first character)
- substituting fallback characters
- being blazingly fast (binary search)
NormalizationMapping
This Resource is our database of replacements, used by the UnicodeNormalizer.
It is built from the official unicode.org data.
It is only about 16Kio, and is derived from 1.9Mio of raw data.
Basic Usage
You can use the normalize method on the autoload singleton UnicodeNormalizer:
UnicodeNormalizer.normalize("Dès Noël, où un zéphyr haï me vêt")
# "Des Noel, ou un zephyr hai me vet"
Advanced Usage
The UnicodeNormalizer is made to be extended, to be tailored to your font capabilities and needs.
Here, the font supports some french diacritics, but only uppercase characters:
# file "MyFontNormalizer.gd"
extends UnicodedNormalizerNode
var characters_in_my_font := "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ÉÈÊËÀÂÄÔÖÙÛÜÇ"
func should_skip_character(character: String, _character_code: int) -> bool:
return self.characters_in_my_font.contains(character)
func normalize(some_string: String) -> String:
return super.normalize(some_string.to_upper())
This is a naive/inefficient implementation to keep the example short and simple. A more performant implementation would use binary search on a sorted array.
Testing & Benchmarking
See tests/.
It is safe to delete that directory if you want to save space in your game.
Contributing
Everything happens on the software forge : https://github.com/Goutte/godot-unicode-normalizer
Achitectural Decisions Records
Case Sensitivity
To keep maximum flexibility, we decided not to cast to lowercase.
It is trivially done in Godot with the method String.to_lower(),
so you can do it yourselves if you need to.
Binary Normalization Mapping
The normalization mapping is provided as a compressed res file, weighing only about 16Kio.
If you'd prefer a tres file (about 75Kio), you can generate it yourselves using the same tools as we did.
You will need to download about 1.9Mio of raw CSV and JSON source files from unicode.org's repositories first.
See NormalizationMapping.from_source() and the test file for information on how to proceed.
Ad Hoc Test Suite
We did not want to depend on a third party addon for tests, since there is no addon dependency management yet in Godot.
The test suite is an EditorScript you can run using CTRL+SHIFT+X.
Tool Annotation
Since our test suite runs in the Editor, we needed @tool.
Then again, you might need to use normalization in the Editor.
We actually did, in the end, so @tool stayed.
Right-to-Left Support
This has not been tested at all. Do make a report if you try it out, whether it works or not.
That's it ! Have fun !
Tookit to handle removing diacritics and substitutable characters from unicode strings.
Provides a UnicodeNormalizer singleton that helps normalize your unicode strings by :
- removing diacritics (decomposing, then keeping only the first character)
- substituting fallback characters
- being blazingly fast (binary search)
- being lightweight
- being extensible
Its replacement database is built from the official unicode.org data. It is only about 16Kio.
Usage Example :
You can use the `normalize` method on the autoload singleton `UnicodeNormalizer`:
UnicodeNormalizer.normalize("Dès Noël, où un zéphyr haï me vêt")
# "Des Noel, ou un zephyr hai me vet"
You can also exclude some characters from the normalization by removing the from the mapping :
var allowed_decomposables := "éàè"
for i in allowed_decomposables.length():
UnicodeNormalizer.mapping.remove_decomposable(allowed_decomposables.unicode_at(i))
Finally, the UnicodeNormalizer is made to be extended, in order to adapt to specific needs.
Reviews
Quick Information
Unicode Normalizer
Tookit to handle removing diacritics and substitutable characters from unicode strings.Provides a UnicodeNormalizer singleton that helps normalize your unicode strings by :- removing diacritics (decomposing, then keeping only the first character)- substituting fallback characters- being blazingly fast (binary search)- being lightweight- being extensibleIts replacement database is built from the official unicode.org data. It is only about 16Kio.Usage Example :You can use the `normalize` method on the autoload singleton `UnicodeNormalizer`:UnicodeNormalizer.normalize("Dès Noël, où un zéphyr haï me vêt")# "Des Noel, ou un zephyr hai me vet"You can also exclude some characters from the normalization by removing the from the mapping :var allowed_decomposables := "éàè"for i in allowed_decomposables.length():UnicodeNormalizer.mapping.remove_decomposable(allowed_decomposables.unicode_at(i))Finally, the UnicodeNormalizer is made to be extended, in order to adapt to specific needs.
Supported Engine Version
4.0
Version String
0.1.2
License Version
MIT
Support Level
community
Modified Date
2 years ago
Git URL
Issue URL